GEoFFREY: Geographic Estimations of Fairly Faultless Rightness Easily Y’know?
By Jan Charatan, Aidan Wu, Melat Feseha, Victor Hernandez Brito, Colin Kirkpatrick
1. Abstract
GeoGuessr is a popular game that involves guessing the location of an image based on a random Street View location. Users use contextual clues such as signs, buildings, and plants to help inform the location they guess. In this project, we attempted to create a neural network (NN) that can take in a random screenshot from Street View and accurately guess the country where the image was taken. To tackle this problem, we scraped a dataset of 110,000 images from 55 countries. Using a convolutional neural network (CNN), we were able to train a model that was able to guess the correct country 59.4% of the time and had the correct country in the top five guesses 85.5% of the time. This tool presents a number of ethical questions, such as potential abuse regarding identifying location from personal social media pictures. We believe the potential risks of this tool can be limited by restricting location estimates to country of origin, rather than specific geographic location.
2. Introduction
While our web app is modeled after the popular browser game GeoGuessr, the ability to generalize the process of geographical estimation from simple image input has many powerful applications. Generally, we rely on known landmarks or stored image metadata to identify the location an image was taken. While these are effective methods, they are not always available to us. Our tool enables us to estimate the location of an image, regardless of whether it was taken in an ambiguous location, even in the complete absence of metadata or visual signals such as street signs or building names. This tool could be used by researchers, hobbyists, and travelers to match media to real-world locations.
We used a dataset that had 2,000 images each for 55 countries to train our NN to identify the country in which the image was taken. When we trained on this dataset, we trained a model that was able to guess the correct country 59.4% of the time and had the correct country in the top five guesses 85.5% of the time. Given the success of this first attempt, we propose improving the dataset and further hyperparameter tuning and experimentation with architectures as possible extensions to this work. We are also cognizant of the important ethical considerations raised by this work, which we will discuss in the Ethical Sweep section.
3. Related Works
There exists previous academic work that has attempted to use NNs to identify the location of an image. Suresh et al.’s paper is very similar to ours—they trained a NN that takes in pictures of the United States and guesses the most probable state using a balanced dataset that equally samples from all 50 states 1. Another paper that was slightly more broad in scope than Suresh et al. is Müller-Budack et al 2. This paper sought to guess geolocation without being limited to a particular country—the NN trained in this paper is notable because it takes into account information from different spatial resolutions.
Another paper that tackles a similar problem to the one we are trying to solve is Kim et al 3. Part of this paper trains a NN to classify tourist attractions to aid in the goal of identifying which parts of tourist attractions are most appealing to foreign visitors. Furthermore, other academic work has sought to solve related classification problems as well. For example, Li et al. used a NN to identify the location of a license plate 4. Miura et al. sought to classify the geolocation of tweets 5.
In industry, Google has received media coverage for their solution to the problem we are tackling 6. They have trained a model called PlaNet that can correctly identify the correct continent of an image 48.0% of the time 7. Finally, we referred to resources on CNNs such as a video by Deeplizard to learn about the approach we should use for our project 8.
4. Ethical Sweep
One of the ethical implications of GEoFFREY is the fact that street-view photos of different countries are disproportionately represented online. Some countries simply have far more available images. Without very deliberate data selection, this could mean that our model would be more accurate with well-represented countries, and less accurate with under-represented countries. In order to avoid this outcome, we paid particular attention to guarantee that our dataset was equally representative of each nation included in our app. Consequently we used equal numbers of training images for each country. Our images were scraped from Random Street View, which only had street-view data from 55 countries. Because this is about one-fourth of the nations in the world, one of the main ethical concerns of our group is that our tool only applies to a relatively small number of countries and not every country as we had initially hoped. This is a testament to how difficult it can be, even with the best intentions, to create tools that are unbiased in the machine learning field. This ethical problem of biased data would result in overfitting; if the model was trained with mostly one or two countries it would overfit for these and not be nearly as accurate with countries that are less represented in the data.
Our model gives a location from a picture, but that has some intended and unintended uses. An intended use is as simple as the application gets: attempting to guess a country with the best accuracy. One of the visions that our team had was to have the model compete against players in the game GeoGuessr, in which users try to guess the country from an interactive street view. An unintended use of the model would be to utilize the application for surveillance purposes; for instance, its employment by law enforcement to arrest and prosecute criminals would be considered a misuse. Another unintended use of our product is its potential use for stalking individuals, specifically finding the location of their social media photos. While there are many other possible applications of our model, our initial intention was to keep it as a fun competitor in GeoGuessr, with no greater societal implications due to the possible, unforeseen ways that the model can be used. While the repository of the web app is public, we are not making it an easily accessible website for the public or advertising it to people outside of our class.
5. Methods
We began by using a Kaggle dataset which contained about 50,000 images from Google Maps that were labeled by country. We then created a Resnet50 CNN using PyTorch Lightning. Other than having a learning rate of 3e-4 and a batch size of 16, we used default values for all hyperparameters. For our optimizer, we used Adam with the same learning rate of 3e-4. In terms of other infrastructure, we used Hydra to pass in hyperparameters to the model and we logged model progress such as training and validation loss with WandB. Additionally, PyTorch Lightning helped us split and load data and do checkpointing.
After being unimpressed by the imbalance of the Kaggle dataset and the biases it was causing in our results, we decided to scrape our own dataset. Using Selenium, we scraped images from a website that generates images from Google Street View. In total, we scraped 2,000 images each for 55 different countries. That gave us a total of 110,000 images of training data. Each image was tagged with its country of origin. We believe this dataset was sufficient in both breadth and width such that our neural net could be accurate at identifying a large number of different countries.
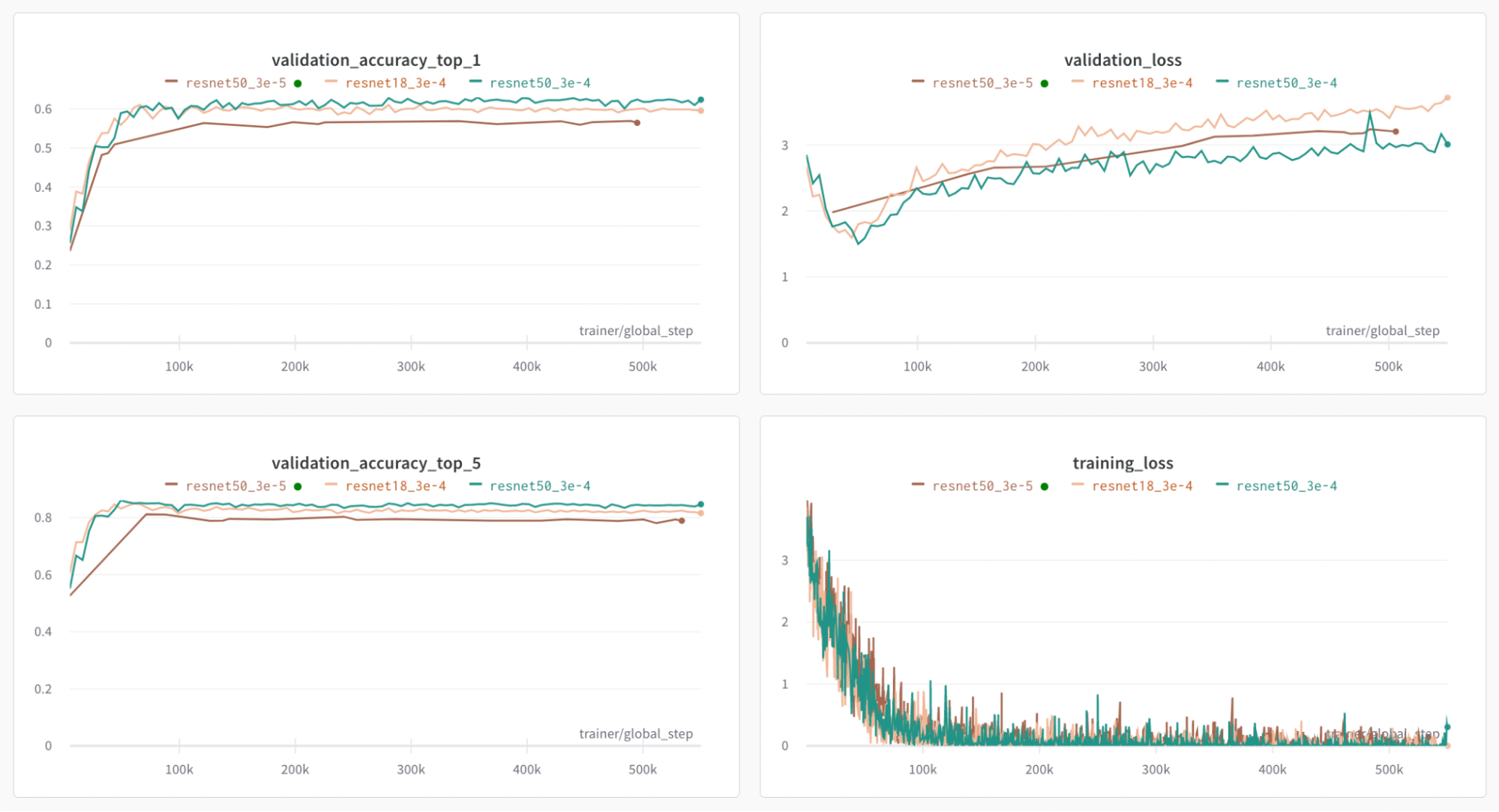
Typically, countries like the United States have far more available data, therefore can be overrepresented in datasets. This can make tools like GEoFFREY biased towards overrepresented nations in their level of accuracy. We paid attention to making sure we had an equal distribution of data for each country so that no one country would be over or underrepresented. This does not guarantee that our neural net will have the same level of accuracy for each nation, but it does take a step towards rectifying the bias that was built into our original dataset. Using this dataset, we tried our Resnet50 architecture and we also tried a Resnet18 architecture. Additionally, for the Resnet50 architecture, we tried a lower learning rate.
The 55 sampled countries are listed below:
| Andorra | Chile | Hong Kong | Netherlands | South Africa |
|---|---|---|---|---|
| Australia | Croatia | Iceland | New Zealand | South Korea |
| Argentina | Colombia | Indonesia | Norway | Spain |
| Bangladesh | Czech Republic | Ireland | Peru | Swaziland |
| Belgium | Denmark | Italy | Poland | Sweden |
| Bhutan | Estonia | Israel | Portugal | Switzerland |
| Botswana | Finland | Japan | Romania | Taiwan |
| Brazil | France | Latvia | Russia | Thailand |
| Bulgaria | Germany | Lithuania | Singapore | Ukraine |
| Cambodia | Greece | Malaysia | Slovakia | United Kingdom |
| Canada | Hungary | Mexico | Slovenia | United States |
6. Discussion
As mentioned above, we began by training our CNN on the Kaggle dataset. At the point where validation loss was the lowest, our model guessed the correct country 43.4% of the time on our validation data and had the correct country in its top five guesses 73.4% of the time on our validation data. Although these results were promising, the problem with the Kaggle dataset is that it is extremely unbalanced and that wealthier nations are overrepresented. For example, the United States makes up 12,000 of the 50,000 files in the dataset. A country like Venezuela on the other hand is only represented in the dataset one time. As we said in our ethical sweep, we were not satisfied with this imbalance since it led to the model simply guessing the overrepresented countries.
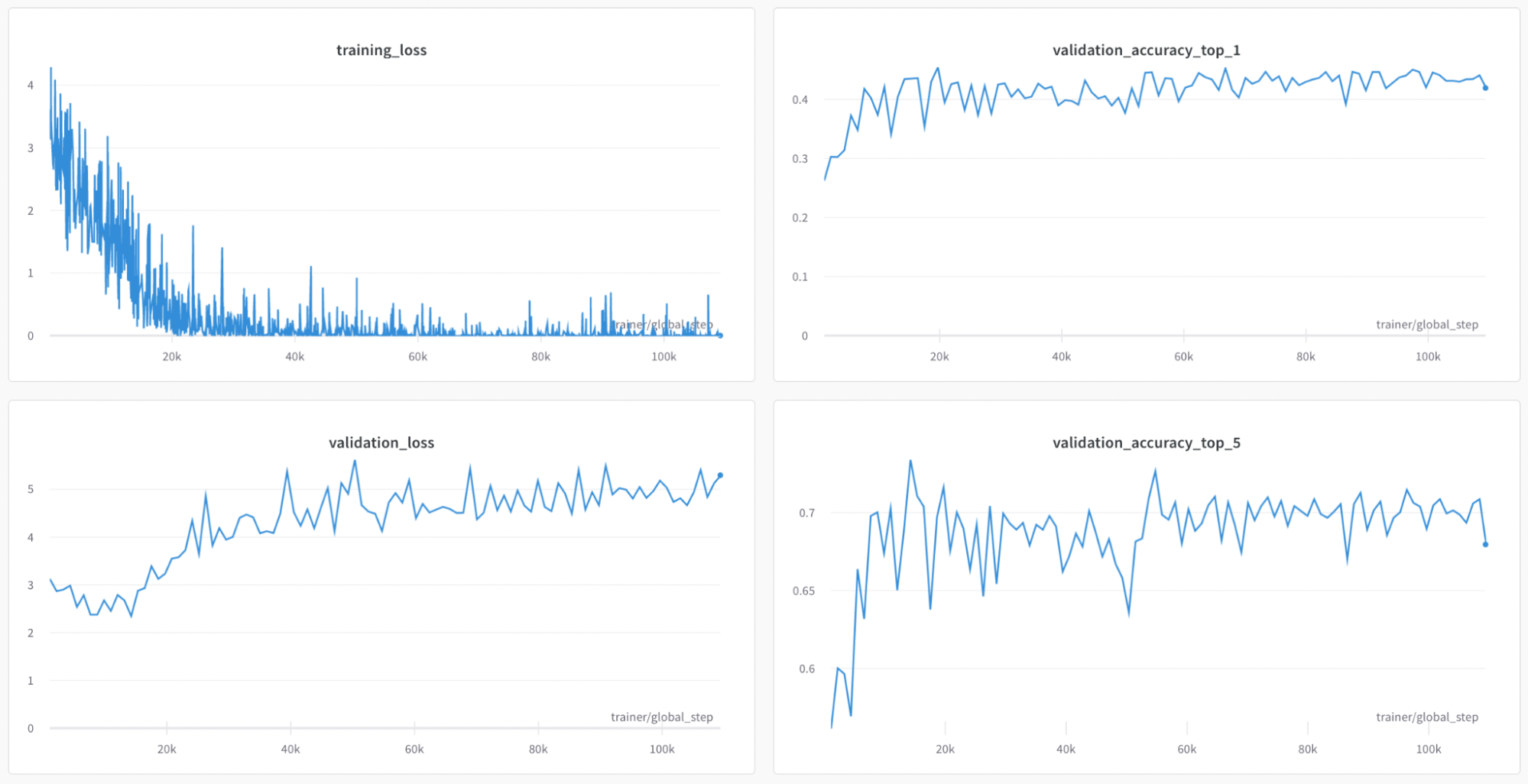
Due to this dissatisfaction with the results of our first attempt at training a NN, we trained a second model on our dataset which contained 2,000 images from 55 countries. We began by training it on the same architecture as before. At the point where validation loss is the lowest, our model was able to guess the correct country 59.4% of the time and had the correct country in the top five guesses 85.5% of the time. Training our model using the Resnet18 architecture and dropping the learning rate to 3e-5 as opposed to 3e-4 did not yield better results so we decided to simply stick with the model we created with Resnet50 and 3e-5 as our learning rate.
We created a simple website that uses our NN to predict countries. Simply upload an image of a street view location and the interface will show the five most likely countries as guessed by GEoFFREY. The repository is located here.

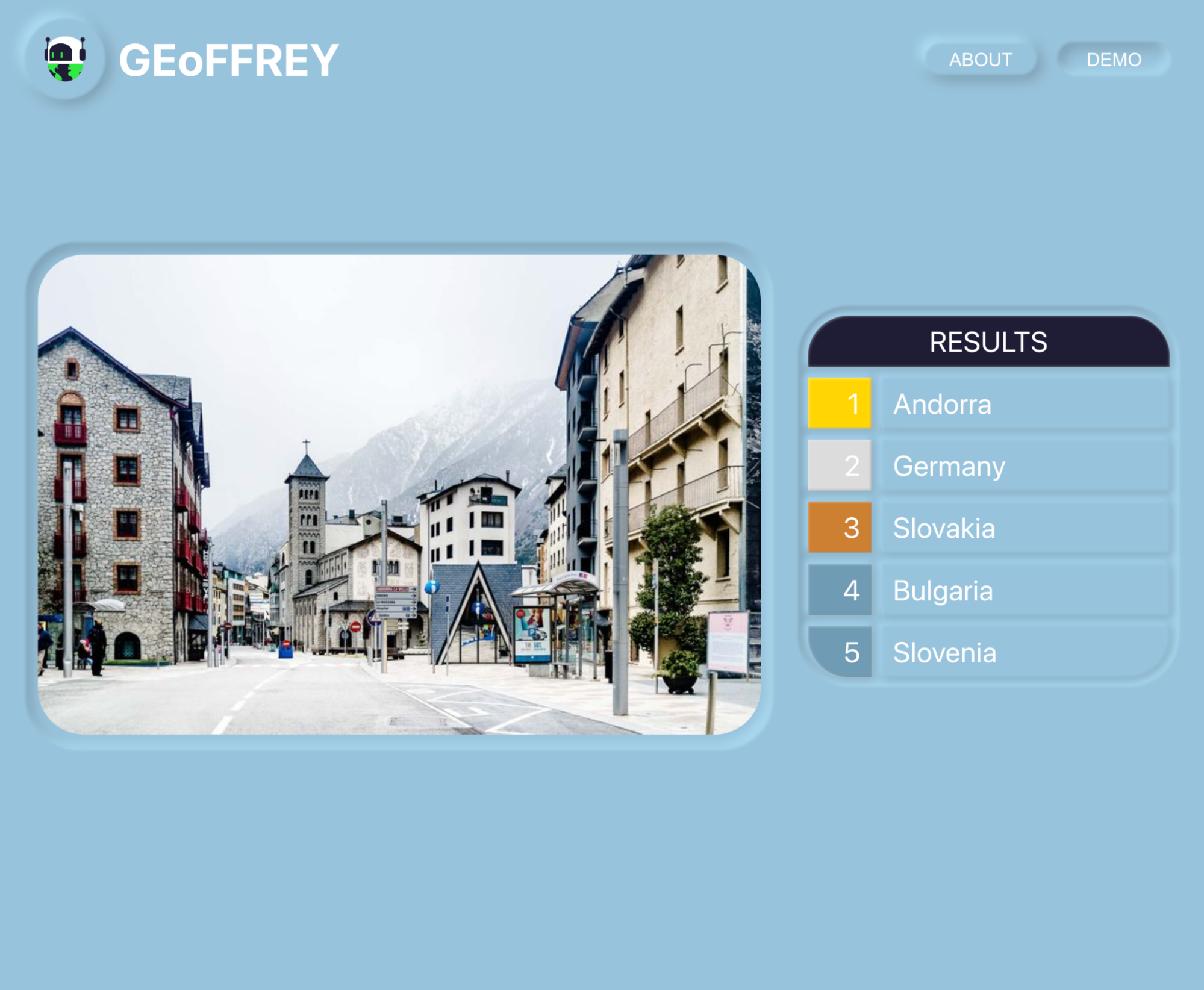
7. Reflection
In general, we were surprised about how accurate the model was with very minimal training: when we first created the network, it guessed the country correctly 43.4% of the time and had the correct country in the top five 73.4% of the time, which is better than we expected the network to do initially. With our balanced dataset, we currently have it at 59.4% top one accuracy and 85.5% top five accuracy. It was really cool to go through the various stages of ideation, to dataset creation, to model creation and then to finally seeing the guesses our model makes on real images.
Some things we would do differently if we had more resources and time would be to improve our dataset. For one, it would be cool if it would include all of the countries in the world and not just the ones found on https://randomstreetview.com/. Additionally, it would be cool to try to modify our scraper so it collects images from each location at various pitches and angles so that we have more information to use to infer. Finally, given the promising results of our model even on such a small training data set, it would be worthwhile to make a dataset that is millions rather than thousands of images big.
Beyond improving our dataset, future work could also entail a continuation of hyperparameter tuning to increase model accuracy. In addition to that, we also proposed this project with the idea that we would also create a NN that could generate an image based on text input. Our current dataset could be used to do this and it would be interesting to see the results of something like this. We could even try taking a country name, creating an image and then feeding it back into our NN to see if it could recognize the image.
References
-
Suresh, Sudharshan, Nathaniel Chodosh, and Montiel Abello. “DeepGeo: Photo localization with deep neural network.” arXiv preprint arXiv:1810.03077 (2018). ↩
-
Muller-Budack, Eric, Kader Pustu-Iren, and Ralph Ewerth. “Geolocation estimation of photos using a hierarchical model and scene classification.” Proceedings of the European conference on computer vision (ECCV). 2018. ↩
-
Kim, Jiyeon, and Youngok Kang. “Automatic classification of photos by tourist attractions using deep learning model and image feature vector clustering.” ISPRS International Journal of Geo-Information 11.4 (2022): 245. ↩
-
Li, Gang, Ruili Zeng, and Ling Lin. “Research on vehicle license plate location based on neural networks.” First International Conference on Innovative Computing, Information and Control-Volume I (ICICIC’06). Vol. 3. IEEE, 2006. ↩
-
Miura, Yasuhide, et al. “Unifying text, metadata, and user network representations with a neural network for geolocation prediction.” Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2017. ↩
-
Brokaw, A. (2016, February 25). Google’s latest Ai doesn’t need geotags to figure out a photo’s location. The Verge. ↩
-
Weyand, Tobias, Ilya Kostrikov, and James Philbin. “Planet-photo geolocation with convolutional neural networks.” Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part VIII 14. Springer International Publishing, 2016. ↩
-
Deeplizard, “Convolutional Neural Networks (CNNs) explained.” YouTube, 9 December, 2017. ↩